
Token-Based Replay
Token-Based Replay
基于token重演的一致性检查技术。
Mapping
一致性分析的先决条件就是保证模型中的任务和日志中事件之间的映射关系,这个映射关系用label表示。可能存在的映射关系如下:
- 简单的一对一映射:任务仅与一种类型的日志事件相关联,并且模型中没有其他任务和相同的日志事件相关联;
- Duplicate Tasks:模型中的多个任务关联同一类型的日志事件,这意味着他们可能不同,但是在日志中无法区分它们的发生情况。重复任务仅仅在映射关系中存在,在实际的流程模型中是不存在的,因为在流程模型中的所有任务之间都是可区分的。(此时对应为两个或多个任务对应为相同的标签值);
- Invisible Tasks:不可见任务,因为日志中没有对应的日志事件与其关联(因为流程中的某些步骤无法观察到)、或者充当路由使用而引入的不可见任务。
所有与模型中任务无关的日志事件都会被删除(让模型流程的表示粒度和事件日志的表示力度保持相同)。
Two Dimensions of Conformance: Fitness and Appropriateness
一致性方面最主要的问题是:日志是否适合模型。直观的一致性概念衡量模型和事件日志之间的适合度。
共有两个维度来进行评估模型和日志的一致性:Fitness、Appropriateness。
- Fitness:日志跟踪可以与流程模型指定的有效执行路径关联的程度,日志中的每个trace是否都是相对于流程模型的可能执行序列
- Appropriateness:过程模型描述观察到的行为的准确性,以及其表示的清晰度。(反面教材:花模型,可以涵盖一切日志中的trace,但是不够具体,不能清晰的表示日志的行为)
Fitness
Fitness评估的是: 日志中的每一条轨迹是否都是流程模型可能的执行序列。
日志重放?
这种重放过程是以非阻塞的方式、基于日志的视角进行的,即对于trace中的每一个日志事件,都会触发模型中的相应的变迁,而不关心模型的当前正在执行的路径是否被遵循。
模型中的重复任务?不可见任务?如何在重放中解决这个问题?
因为在重放过程中,位于trace中的某一个日志事件,可能对应于模型中的多个任务,无法判断应该启动哪个任务?(只启动一个就行)
在重放中,模型中的隐形任务,没有任何一个日志事件能与其对应,所以在重演过程中,该在什么时候触发隐形模型?(隐形任务被视为懒惰的,当只有能够启动相关变迁的时候才能正确的触发它。)
可以考虑使用状态空间的部分探索,解决上面的这些问题。
在模型中重播trace并记录下来重播过程中丢失的token、生成的token、消耗的token、剩余的token,然后按照下述公式进行计算:
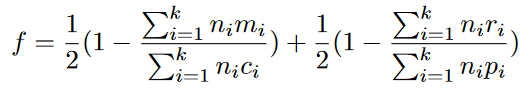
单纯使用Fitness的不足之处?
导致此方法不准确的因素在于重演过程中丢失令牌数、剩余令牌数(m、r),所以 如果给出花模型、轨迹穷举模型,则最终一定是1,但是并不见得这两种模型一定适合描述我们的事件日志所代表的流程。
定位问题?
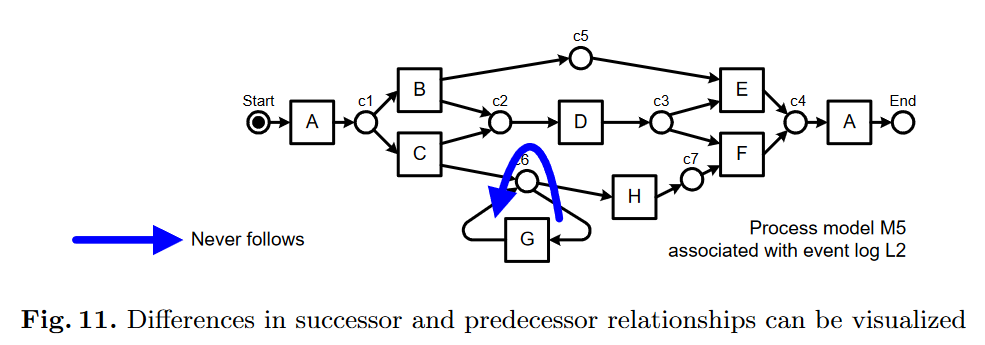
可以根据trace在日志中重演的过程,确定出问题的地方,以方便提出一些诊断性建议。可以在图中标出哪个place缺失token、哪个place在重演结束后仍有剩余的token、哪个变迁是异常执行的?如下图所示,在重演结束后,c6处剩余51个token、c7处缺失51个token:
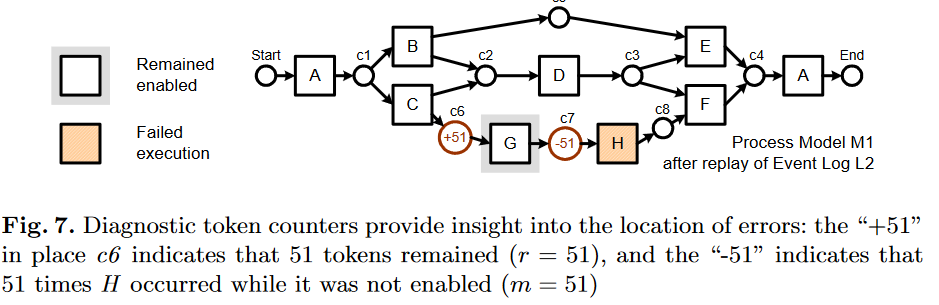
提出来的诊断信息需要领域专家进行解释说明并鉴定。
Appropriateness(适当性)
适当性有两种。结构适当性,行为适当性。
Behavioral Appropriateness(行为适当性)
行为的适当性评估的是: 模型允许多少除日志行为之外其他的 额外的行为(即不正确的行为,即在事件日志中不存在的行为,但是流程模型却允许的行为),目的是尽可能精确的对流程模型进行建模,减少没必要的模型语义。如果模型过于笼统,从而无法精确的表示日志中的行为,这样模型所携带的信息量就会过少,并且允许过多的不需要的执行序列,例如:花模型、穷举模型。
从两个角度分析额外行为这种一致性问题:
- 模型允许的“额外”行为可能对应于,例如,处理在日志记录的时间范围内没有发生的异常情况的替代分支。(日志缺失信息,模型完整)
- 模型过于通用,考虑到了现实中从未发生过的情况。(模型允许额外的垃圾流程执行,模型的问题)
领域专家必须能够区分这两种情况,因此需要引入一个指标来测量模型涵盖的可能行为的数量。通过日志重演期间启用的变迁的平均数量来衡量。因为选择结构、并行结构、潜在的行为的存在可能导致重放日志期间启用的变迁数量增加。
Simple Behavioral Appropriateness(简单行为适当性)
简单行为适当性用于:衡量模型灵活程度的适当性。即模型允许的行为越少,该模型越好!对于纯粹的顺序模型,简单行为适当性的评估结果为1
- :日志中不同 trace 的数量
- :组合到当前trace中的流程实例的数量
- :当前跟踪的日志重播期间启用的变迁数的平均值(请注意,不可见任务可能会启用后续标记的任务,但它们本身不会被计数)
- 例如,重演一个含有n个事件的trace,在模型重演过程中,每执行一个task都会启用后续的任务。我们记重演当前trace时,每次执行一个task后,启用的任务数的平均值用表示
- :Petri网中可见的任务集合
简单行为适当性度量的计算公式如下所示:
的范围从0到1,0代表类似于花模型(模型中所有可见任务在日志重播期间始终可用,欠拟合);1代表顺序模型类似的穷举模型(过拟合)。
这个指标的不足之处:该指标对于通过重复任务对模型进行排序的情况并不稳定,例如图b模型M3,构成的穷举模型:
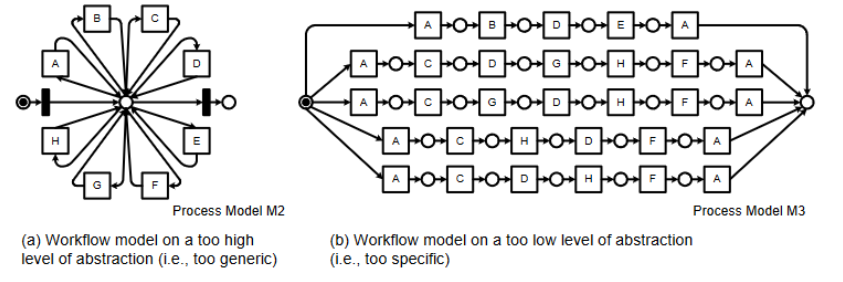
Advanced Behavioral Appropriateness(先进的行为适当性)
对模型指定的潜在行为进行分析,并将其与事件日志中观察到的实际行为进行比较。并且为了弱化对日志的完整性要求与确保准确捕捉远距离关系,使用全局的先后跟随、先于关系。
查看一组序列,确定两个活动(x, y)是否 始终、从不、有时 ("始终、从不"体现了硬约束,"有时"体现了变化)在彼此之前或之后。提出两个关系:Follows Relations、Precedes Relations:(基于全局的前驱、后续 的关系,不会要求必须要存在紧密的先后关系这种情况)
- Follows relations:遵循关系(前后关系,后缀)
- Precedes relations:先于关系(往前看的关系,前缀)
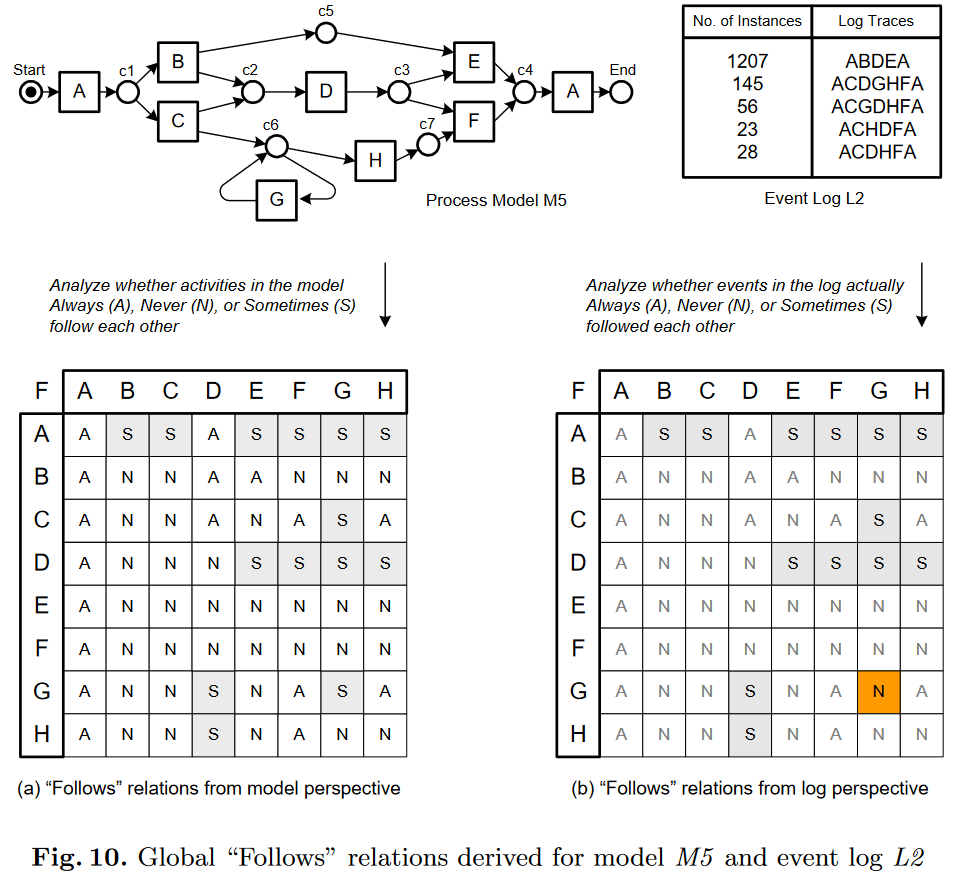
其中对M5模型和事件日志L2,导出的所有活动之间的Follows Relations关系如下所示:
- 模型,需要对模型分析其可能的执行序列(基于状态空间分析或 模型的穷举模拟),然后再进行分析Follows关系,其中这种分析过程肯定非常耗时(跟Log相比)。
- 日志:直接分析从日志中观察到的执行序列。
公式计算:
由于计算考虑的是行为的可变性,所以关心的是 sometimes 关系而不是 Any 和 None。以下度量的目的是根据 和 关系的基数,比较模型所允许的行为和日志中观察到的行为的可变性。
- 代表Follow中的Sometimes关系
- 代表Precedes 中的Sometimes关系
- 代表Follow中的Sometimes关系(模型的)
- 代表Precedes 中的Sometimes关系(模型的)
- 代表Follow中的Sometimes关系(日志的)
- 代表Precedes 中的Sometimes关系(日志的)
高级行为适当性度量公式如下:

**公式的原理:**上述的公式,完美的定位了适配性问题,例如:两个活动在模型中是sometimes关系,在日志中是A或者N关系,或者两个活动在模型中是A、N关系,在日志中是sometimes关系,这都属于适配性问题。
**可以诊断模型出现问题的位置?**按照基于全局的Follows和Precedes关系可以建模出,模型中从未使用的选择、并发部分。如上图10所示,在模型中允许GG之间具有Follows、Precedes关系,但是在Log中显然不允许这种关系。所以在Model中标注出来:
依赖于这种新的度量方式,花模型也可能相对于某些表现出随机性较强的事件日志而言,也是一个很好的模型。
Structural Appropriateness(结构适当性)
结构适当性,模型的结构可能存在许多的潜在问题,例如:不可见任务、隐形place、重复任务,这些问题的存在可能会影响模型的表达能力,所以需要对模型的整体结构进行评估。
- 隐形库所:隐形库所指的是可以在不改变模型行为的情况下删除的库所。过程发现算法很难检测到不可见库所、沉默库所。
- 隐形任务:除了用于路由目的的隐形任务外,还有一些隐形任务只会延迟可见任务。如果这些任务没有其他用途,可以直接删除,从而使模型更加简洁。
- 重复任务:用大量的重复任务表示流程模型,妨碍了模型的抽象性,模型表意不清。
Simple Structural Appropriateness(简单结构适当性)
L:模型中任务和日志中事件之间的映射标签集合
N:模型中的节点集合(Place、Transition)
简单结构性计算公式如下:
Model中无用的节点越多,的值越接近0。该指标只能用作表现出等效行为的流程模型的比较手段(要比较的模型之间一定是等效模型!),因此,其适用性有限。
评估模型的结构适当性,验证是否满足某些设计准则,某些设计准则:
- 避免使用替代性重复任务
- 避免使用冗余隐形任务
- 这些行为会膨胀流程模型的结构、降低所表达行为的清晰度
更完整的描述(该方法的正式规范)可以在技术报告[31]中找到。请注意,由于模型中的路径数量可能变得非常大,因此检测选择结构的重复任务的成本可能会出现问题。相比之下,冗余的隐形任务可以通过模型的结构分析来检测,这通常非常快(参见第 7.2 节了解一些复杂性指示)。
Advanced Structural Appropriateness(先进结构适当性)
- :Petri Model中的所有变迁集合
- :alternative duplicate tasks集合,模型中选择结构的重复任务集合
- :冗余隐形任务集
Balance Fitness and Appropriateness
fitness、behaviour Appropriateness 和structior Appropriateness 是相互正交的。它们衡量的是完全不同的东西,因此,根据一种概念做出的改进与根据另一种概念做出的改进并不具有可比性。
在实际情况中,fitness维度更占优势,所以建议分两个阶段进行一执行分析:
- 首先分析fitness维度
- 评估模型的appropriateness维度
Petri网分析先验知识
Petri 网的分析方法为以下三类:
- 可覆盖性(可达性)树方法;
- 矩阵方程方法;
- 还原或分解技术。
第一种方法主要是枚举所有可达标记或其可覆盖标记。这种方法适用于所有类别的网络,但由于状态空间爆炸的复杂性,它仅限于 "小 "网络。矩阵方程和还原技术非常强大,但在很多情况下,它们只适用于 Petri 网的特殊子类或特殊情况。
The Coverability Tree
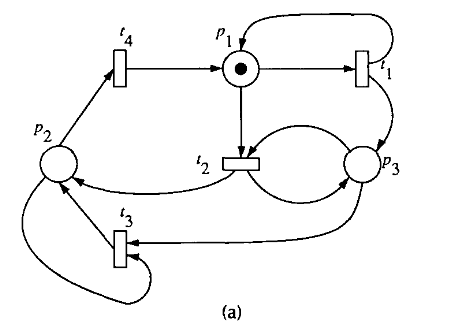
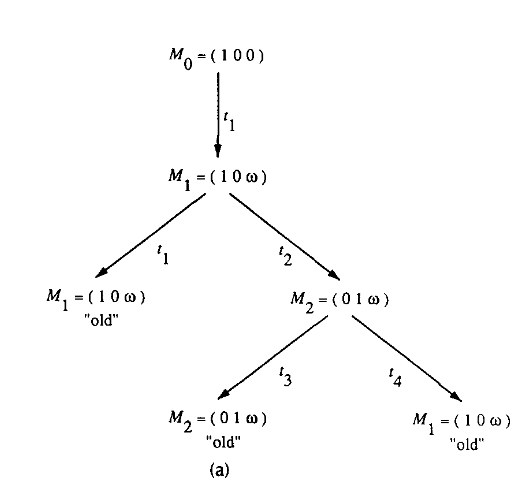
节点代表从 M0(根节点)及其后继节点生成的标记,每个弧代表一个变迁触发,它将一个标记转换成另一个标记。如果网络是无限的,那么覆盖树将无限扩大,引入一个 ,代表无限大。
Petri网的可覆盖性树按照下面的算法步骤搭建:
- 将初始标记 标记为根,并标记为新。(标记指的是 Petri网库所中的token,标记数是token数)
- 在 "新 "标记存在的情况下,执行以下操作:
- 选择一个新标记 M。
- 如果 M 与从根节点到 M 的路径上的标记相同,则标记 M 为 "旧 "标记,并转到另一个新标记。
- 如果 M 处未启用任何变迁,则标记 M 为 "死路"。
- 如果 M 处存在已启用的变迁,则对 M 处每个已启用的变迁 t 执行以下操作:
- 获得在 M 处触发 t 所产生的标记 M'。
- 在从根节点到 M 的路径上,如果存在标记 M",使得 M'(p)>=M"(p),且 M' != M",即 M "是可覆盖的,则对于每个 p,用 w 替换 M'(p),使得 M'(p)>M"(p)。
- 将 M' 作为节点,从 M 到 M' 画一条标有 t 的弧,并标记 M' 为 "新"。
根据Petri Net获取到的覆盖树图表示为:(V是节点集、E是边集,其中每一个代表从第一个标记到达第二个标记所对应的触发变迁,)。如果Petri Net是有界的,那么,其中代表从初始标记可到达的所有标记情况。
Petri Net转覆盖树图的案例:
Adding Conformance to the ProM Framework
在ProM框架中实现 Conformance Checker,用于在ProM中内置Token Replay一致性检查器。
Conformance Checker 以非阻塞方式重播 Petri 网模型中的事件日志,同时收集随后可以访问的诊断信息。它计算基于令牌的fitness度量 f(考虑每个日志跟踪的流程实例数量)、行为适当性度量 aB 和 a'B,以及结构适当性度量 aS 和 a'S。
在日志重播期间,插件负责处理不可见的任务,这些任务可能使转换能够在接下来重播,并且它能够处理重复的任务(另请参见第 7.2 节)。
Implementation of the Conformance Analysis Plug-in
提供了用代码实现计算 token replay 指标的方法。具体的分析计算方法如下:
状态空间分析:遍历流程模型的可覆盖性图,可以用于计算两个指标,但是模型的状态空间可能呈现出指数级别增长,因此这个方法在计算复杂度方面存在性能问题。
- 计算复杂度方面的解决方案:部分阶缩减法、对称方法(partial order reduction, and symmetry methods)
结构分析:分析流程模型的结构,这用于度量和,冗余隐形任务是通过基于文献[27]中的描述进行分析出来的,结构分析技术相比较于状态空间分析而言,效率很高。
日志重放分析:日志重放分析,以非阻塞的方式从日志角度重放日志,计算指标、,要从日志角度得到指标的活动关系,只需要一次通过日志即可,不需要实际的日志重放。
无隐形或重复任务的日志重放方法的时间复杂度仅随日志大小的增加而线性增加。这对实际应用非常重要,因为它还能对大型日志进行分析。但是,如果日志重放涉及隐形或重复任务,在重放过程中可能会出现需要部分探索进程模型状态空间的情况,这可能会降低性能。
Log Replay Involving Invisible and Duplicate Tasks
- 特定任务是否可以通过启动一系列不可见任务来启用
- 在重复任务中选择一个任务的决策
Enabling a Task via Invisible Tasks
不可见任务被视为 "lazy ",即它们可能会触发以启用其后续的可见任务(请注意,不可见任务绝不会在日志重放流程中直接触发,因为它们没有相关的日志事件)。
这就意味着,如果当前重放的任务没有被直接启用,那么在认为该任务失败之前,必须检查是否可以通过一系列不可见任务启用该任务。多个启用序列之间的冲突可以通过从最短序列集合中任意选择一个元素来解决。这样做的目的是尽量减少对当前网络标记可能产生的副作用,例如,避免不必要地启动一个与稍后重演的另一个任务相冲突的不可见任务。图 4.8 显示了在 DiagnosticTransition 中实现的 isEnabled() 方法的流程。
由于诊断变迁 也可以 "通过 "一个或多个不可见任务来启用,因此要创建一个列表(空列表的长度为 0,但不是未定义)来捕捉这种(潜在的)启用序列。
- 如果变迁还是启用了,则该序列保持为空,该方法返回 true;
- 如果当前变迁未被直接启用的情况下,状态空间是根据 Petri 网的当前标记建立的。为了防止累积标记的网络产生无限的状态空间(例如,在构建 Petri 网的可达性图时可能会出现这种情况),我们使用了 ProM 框架的可覆盖性图生成器来实现。在可覆盖图中,所谓的 ω 状态指的是扩展标记,它包含了无限标记中标记累积产生的所有不同的有限标记[30, 33]。
Labeled Transition System?
Labeled Transition System 表示为:,其中S是状态集,是状态变迁集,T是变迁名字的集合,L是变迁标签的集合,是标签函数(只有在 dom(l) 中的才是可见变迁),假设有唯一的起始状态和结束状态。